Watermarks That Survive Background Replacement
24 June 2026Instead of spreading digital watermark across the entire image, this method embeds it only in the semantic foreground (the person), making it immune to AI background replacement.
Reference Paper: A Semantic-guided Watermarking for Portrait Images
Introduction
Imagine you upload an image of yourself online and the image has a digital watermark embedded into it. Now imagine someone takes that image and perform background replacement on it, swapping your messy dorm room for a mountain landscape - altering a majority of the image pixels in the process. The watermark is destroyed and the manipulated image can be used for identity theft, misinformation, or fraud.

In the era of generative AI, where background replacement tools are readily accessible, this problem is no longer hypothetical but a real-world concern. And the work “ A Semantic-guided Watermarking for Portrait Images ” addresses it by prioritizing regions of the image that bears the semantics of the portrait and are not easily expendable.
Why Existing Approaches Fall Short
Traditional image watermarking techniques, often called the global image watermarking (such as HiDDeN , IGA , SteganoGAN , ReDMark , etc), embed the watermark into the pixels of the entire image. As more pixels carry the signal, it is harder for random noise (JPEG compression, blurring, generic noise, etc) to wipe it out. However, it has poor robustness against semantic edits, where an attack rewrites one meaningful part of the scene and preserves another.
On the other hand, local image watermarking techniques embed the watermark in specific regions of an image. These specific regions can be selected in two ways: manually or feature-based. In case of manual selection (mostly in medical imaging), it is completely human-driven and not scalable at all. And for the feature-based selection methods (based on saliency , SIFT keypoints , texture complexity , etc), although they are feature-aware, they are not semantic-aware. But a region can be “feature-rich” without being the most semantically important region of the image. For example, in a portrait, a textured background may be full of strong features, but semantically it is not the most important region.
So, the existing approaches fall short focusing on the semantically significant portion of the image, which is likely to be preserved by the bad actor.
The Core Idea: Embed Where It Matters
The central idea in this paper is very simple: embed the watermark where it matters, which is the region of the image that is semantically important and thus more likely to be preserved after any modifications (such as background replacement). And if the semantically important region itself gets modified, then the meaning of the image changes entirely, nullifying the need of the watermark.
The proposed method includes the following core steps to achieve the above:
-
Identify Semantic Region
The local guidance modules help to identify the semantic region (the portrait) at both embedding time and extraction time — even after the image has been attacked.
-
Embed Into Semantic Region
The encoder embeds the watermark into the identified semantic region.
-
Extract From Semantic Region
The decoder attempts to extract the watermark from the identified semantic region.
Architecture
The framework follows the encoder-noise-decoder paradigm popularized by HiDDeN, but wraps it with two novel guidance modules (EG & DG) that make the entire system semantics-aware.
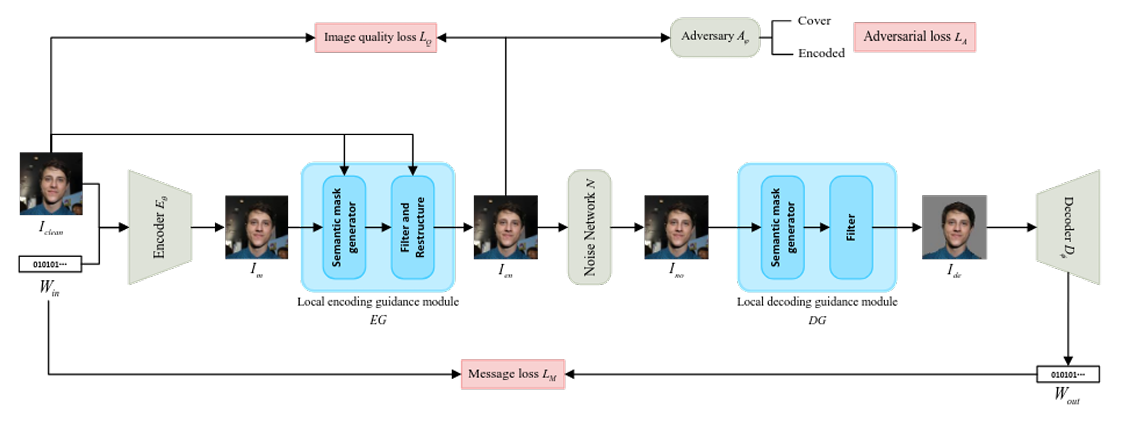
The pipeline has six key components:
-
Encoder (E)
Takes the original image and a binary watermark, produces a preliminary watermarked image
- U-Net inspired design to preserve fine structural details (edges, contours)
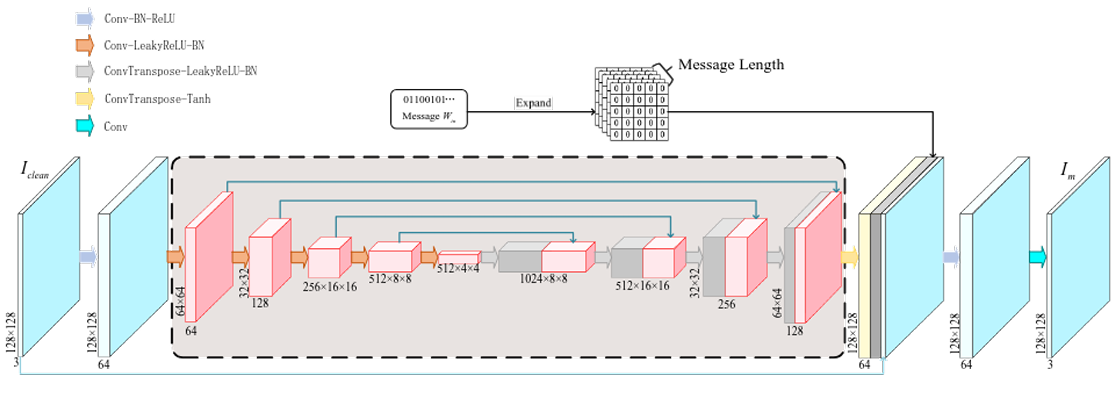
Figure 3. Encoder Architecture -
Local Encoding Guidance (EG)
Masks the encoder’s output, keeping watermark perturbations only in the semantic region
- Used a pre-trained portrait segmentation network called SINet to generate the semantic mask
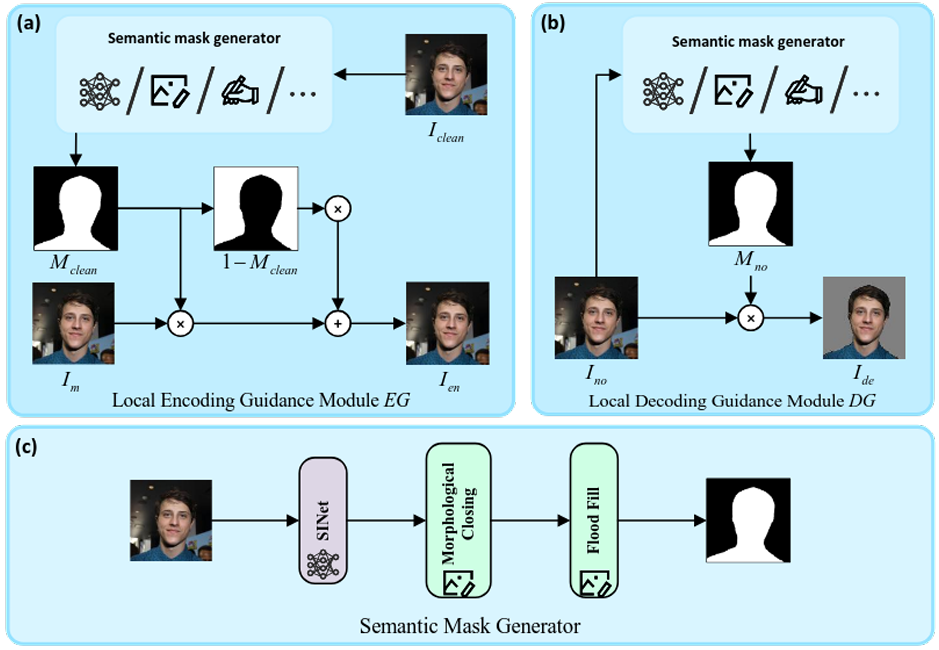
Figure 4. Local Guidance Modules -
Noise Layer (N)
Simulates real-world distortions during training, forcing the encoder-decoder pair to be robust
- During each training step, one of these seven types of noise has been randomly applied: cropout, gaussian blur, gaussian noise, brightness, contrast, saturation, and hue adjustments.
-
Local Decoding Guidance (DG)
Masks the noisy image before decoding, so the decoder only sees the semantic region
- Without this step, the decoder may receive a full image with a replaced background and infer that the watermark is not present
-
Decoder (D)
Extracts the binary watermark from the masked, possibly distorted image
- A relatively standard convolutional network with residual blocks has been used as decoder
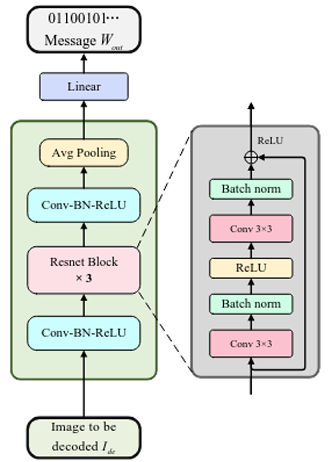
Figure 5. Decoder Architecture -
Adversarial Discriminator (A)
Pushes the encoder to produce watermarked images that are visually indistinguishable from originals
- Have the total loss balancing three objectives: image quality, message reconstruction, imperceptibility
Limitations
-
The method is tailored to portrait images and depends on a reliable semantic mask. So, the watermarking system is bounded by the segmentation model’s accuracy and inherits the limitations too.
-
Although it is robust to background replacement, other types of distortions, especially nonlinear noise, can still affect it adversely.
-
The work does not evaluate screen-capture attacks, which are important in real-world deployment.
-
Harder semantic edits such as face retouching, face swapping, reenactment, or partial identity changes remain an open and more difficult challenge.
Takeaway
To defend against semantically aware adversaries, your defense strategy must also be semantically aware. The work shows that semantic-aware watermarking is possible through local guidance. In this case, a segmentation model that generates the semantic mask.